Course Lessons
chapter 6 : Correlation
Spearman Correlation (ρ or rₛ)
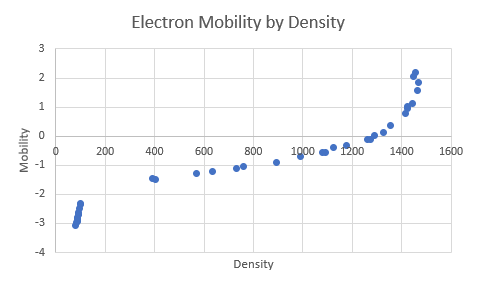
Measures ranked or ordered relationships — i.e., how well the order of one variable matches the order of another.
Good when data isn’t linear, not normally distributed, or when variables are ordinal or ranked.
Based on ranks rather than raw values.
Example: Ranking students from top to bottom in two tests and checking how similar the rankings are.